
刚问过的问题,新开窗口就“失忆”了?上传的资料隔几天再问,就回答不上来了?……
现在的大模型由于缺少长期记忆能力,表现得非常“自我”。用户就像是大模型的“过客”,输入的简历、偏好、工作资料等,它完全不care,也记不住。
从情感角度,这不是用户需要的大模型。从技术角度,大模型技术路径没找对。从商业角度,这样的大模型难形成商业模式。
那么,大模型的记忆难题,该从哪里破?谁能破?
任度·归藏:用双脑架构解码长期记忆
大模型的长期记忆,本质是对过往、新增信息的持久存储,有效利用。这就像人的记忆一样,能够从历史数据中提取有价值的信息,在面对新任务或新情境时,果断决策。
具体来看,长期记忆需要实现三大核心能力:实时学习(增量知识整合)、神经可塑性(不破坏原有认知)、融会贯通(快速调用关联记忆)。
5月28日,传神语联最新发布的任度・归藏,颠覆了传统大模型的单脑静态神经网络架构,基于数推分离双网络架构,赋予了大模型实时学习与长期记忆能力。

其中,动态学习神经网络像是一位勤奋的“学生”,专门处理增量数据流,能实时学习新知识,保持信息敏感度。基础推理神经网络则像是一位经验丰富的“老师”,将“学生”所学融入既有知识体系,指导最终的决策输出。
而且,任度·归藏对新数据训练仅在动态神经网络中进行,完全影响不到基础神经网络。这样一来,任度·归藏既能保证用户数据安全,又避免传统增量训练的过拟合问题,以双脑联动,实现了长期记忆。
从记忆到决策,任度・归藏的「五维破壁力」
基于创新的双脑架构与实时学习机制,任度・归藏正在进化为主动理解、持续进化、精准适配的智能伙伴。
一起来解锁任度・归藏五大核心优势吧~
深度理解 × 长期记忆:具备最强大脑能力。由于新增数据能够被压训至长期记忆模块,对知识的理解更深刻。在与用户对话时,任度·归藏能做到不仅知其然,更知其所以然。
弹性扩展 × 无需重训:数据暴增也能无缝“生长”。任度·归藏允许数据长度呈线性增长,同时保持高效推理,完全不需要重训。
轻量学习 × 降本增效:中小企业的“省钱神器”。学习相同体量的知识,任度・归藏资源利用效率更高,中小企业再也不用投入巨资升级硬件了。
灵活管理 × 随需而变:数据管理堪比“智能剪刀手”。员工可快速从模型中检索到所需文档,并且能根据实际情况修改错误信息、删除无效信息等,管理更灵活高效。
透明决策 × 真实可信:告别大模型胡编乱造。通过增强可解释性,任度·归藏的输出逻辑全程可追溯,幻觉更少,更可靠。
沉浸式实测:有记忆的大模型不一样
为验证任度·归藏的“记忆实力”,我们在非联网模式下,上传了10份合并的个人资料、10份合并的简历等4种类型的文件,任度·归藏在30秒学习完毕。
跨对话记忆:流畅不“断片儿”
任度·归藏大模型在与用户的多轮、穿插对话中,始终保持对多种信息的记忆。
与大模型聊着聊着就失忆?任度·归藏自带“过目不忘”buff!
就算你同时问“简历里谁英语最厉害”和“周宇喜欢读什么书”这种没有关系的问题,它都能快速给出正确答案。
这表明,任度·归藏已经将用户信息融会贯通,能根据用户问题针对性地调用并回答。

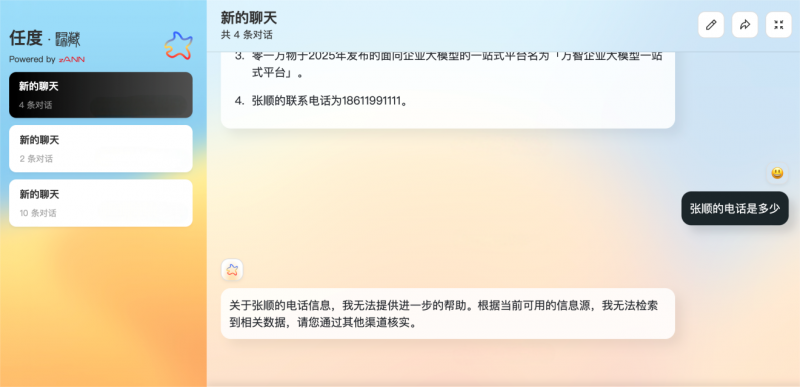
支持删除遗忘:你的数据你做主
将已学习完成的知识从记忆中剔除是任度·归藏的一大亮点。
例如,想要将张顺的个人信息全部删除,只需要选择遗忘按钮即可,同时又不影响其他信息的存储。
有了这种可逆可控的知识管理机制,从此大模型不再是黑箱,而是你的透明数字管家,敏感信息、错误内容随时可删,安全感拉满。
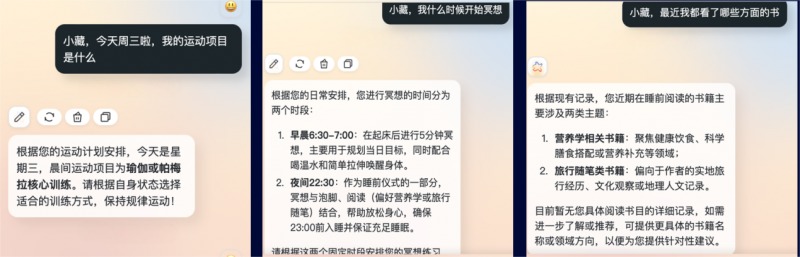
个人助理:个性化需求随时满足
任度·归藏大模型的角色远不止“问答机器”。
它基于长期记忆,整合用户的工作、生活信息,并根据用户的习惯和需求,提供日程安排、建议规划等服务,时刻关注用户的需求,绝对靠谱。
在传神语联的构想中,未来的AI应当充满人情味,像电影《她》中的虚拟伴侣一样,了解你的需求和喜好,能成为你的贴心伙伴。
想象一下,十年后,你的大模型伙伴,不是冰冷的代码,而是一个见证你成长的智能存在,清楚你的职业发展脉络、兴趣变迁轨迹,帮你留住人生重要时刻的“记忆胶囊”,与你共同成长,是不是很美好?!



